データベース管理ソフトSQLite 3の使い方
化学系の方ですと、「データベース」という単語に馴染みがない方もいると思います。 ですが、近年話題の「ビッグデータ」のニュースなどで実は触れているのではないでしょうか。 もしくは、「○○社のデータベースがハッキングされてデータが流出した」などといったサイバー犯罪に関するニュースなら聞いたことがあるでしょうか。
データベースとは、データを蓄積したファイルを指します。 蓄積したデータは後日参照する事が多いです。 例えば、webサービスのユーザーログイン時には既に登録されているユーザー情報と入力されたユーザー情報がマッチするかどうか照合します。
データベースに似た役割を果たせるものとしてMicorsoft Office Excelや、データ管理ソフトとしてMicrosoft Office Accessというものがあります。 .txtファイルにコンマやタブ区切りで構造化された情報が書かれたテキストファイルもある種のデータベースと言えます。
この記事では、データベースを管理するソフトのひとつであるSQLite 3について説明します。 SQLiteとは、リレーショナルデータベースと呼ばれる形式のデータベースまたはデータベース管理ソフトです。 Excelのように1行ずつデータ1個分が格納されます。 1列は1変数に対応し、データ操作に用いるコマンドはまとめてSQLと呼ばれます。
なお、リレーショナルデータベースとして代表的なものに、MySQL, PostgreSQL, SQLite 3がありますが、SQLite 3はその中でも軽量と言われており、比較的小さいサイズのデータを扱うのに適しています。 大きなデータを扱って分子設計等を行う際には、MySQLやPostgreSQLを用いることをおすすめします。 ちなみにAmazon RedshiftやHerokuはPostgreSQLを使っています。
SQLite 3でのデータベース(DB)作成と基本操作
以下の順番で説明していきます。
SQLite 3のインストール
Mac, Ubuntu等では、インストールが容易です。
$ sudo apt-get install sqlite3 # ubuntu
$ brew install sqlite3
Windowsの場合は、.exeファイルをダウンロードページからダウンロードします。
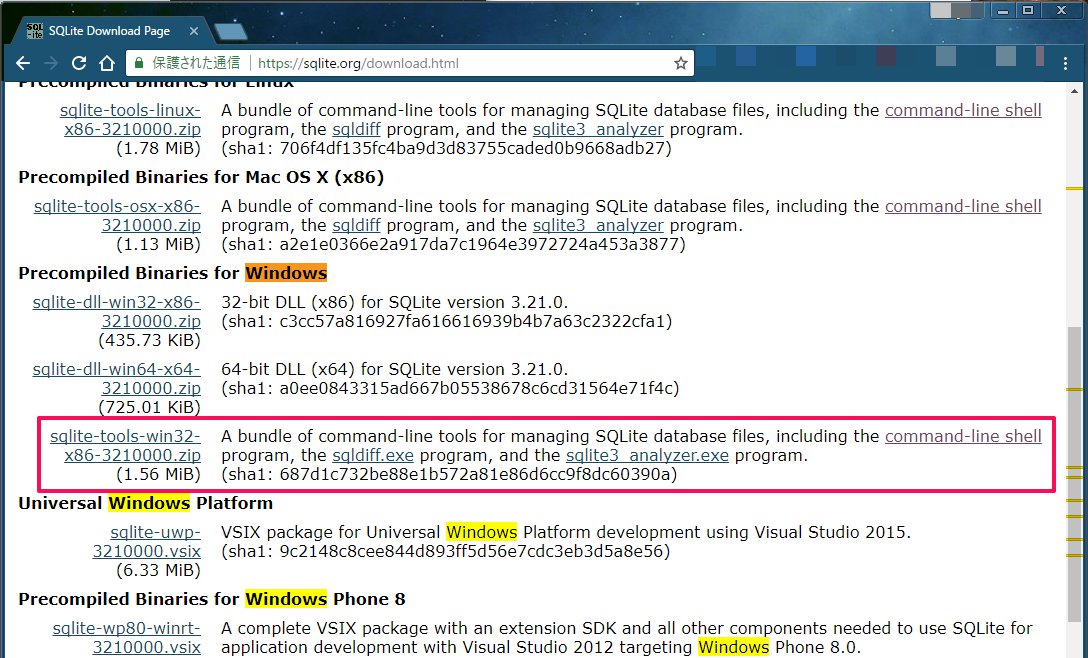
下の図では、SQLite 3のダウンロードページにて、webブラウザ上で”Windows”と入力したときの検索結果を示しています。
赤枠で囲まれた部分のうち、.zipファイルもしくは、”command-line shell”プログラムという部分をクリックしてファイルをダウンロードしましょう。
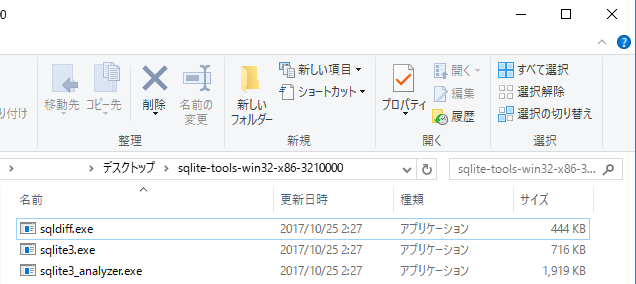
.zipファイルを解凍すると、Windowsでは下の図のようなファイルが見れます。
Windowsでは、この状態がSQLite3をダウンロードした状態となります。
SQLite 3でのDB作成
はじめに、MacやLinux環境でのDB作成方法を説明します。
まず、ターミナル上でsqlite3 sample.dbなどと打ちます。
sample.dbというデータベースファイルがない場合には作成します。
データベースファイルが作成されたのち、sample.dbをsqlite3で開きます。
すると、SQLite 3のコマンドを用いて命令を出すことが出来る、インタラクティブモードへ切り替わります。
ファイルが既にある場合には、既に記録されているデータを読み込むことになります。
$ sqlite3 sample.db
SQLite version 3.11.0 2016-02-15 17:29:24
Enter ".help" for usage hints.
以下ではWindows環境でのDB作成方法を説明します。
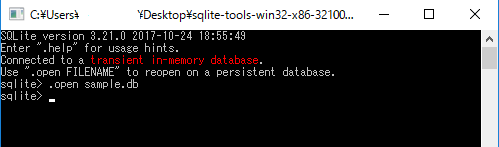
先程の.zipファイルを開いた状態でsqlite3.exeというファイルをダブルクリックしてみましょう。
すると、下の図のような、黒い画面が現れます。
黒い画面は、シェルやコンソールと呼ばれ、SQLite 3のインタラクティブモードに最初から入った状態となります。
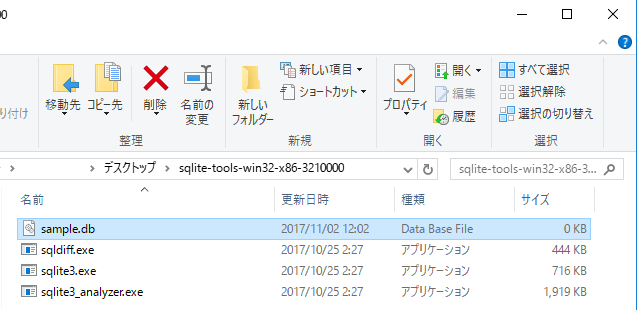
DBを作成する際には、.open {データベースファイル名}と入力します。
今回はMac・Linuxでの例と揃えるために以下のコマンドを打ちます。
sqlite> .open sample.db
すると、以下の図のように、sample.dbファイルが作成されます。
SQLite 3でのテーブル作成
ここからは、例として分子の情報をSQLite 3で作ったデータベースへ格納しようと思います。 Mac・Linux・Windowsのどの環境でも操作は同じとなります。
データベース1個の中には複数のテーブル(表の意味)と呼ばれる領域があります。 Excelファイル1個がデータベースであるなら、その中の1シート分が1テーブルに相当します。
テーブルは格納する情報の種類ごとに作成します。
例えば分子(molecules)と原子(atoms)の情報をそれぞれ格納する場合には、moleculesテーブルとatomsテーブルを作成します。テーブル名は、格納される情報の単位の複数形で名付けることが多いです。
ここでは分子情報を格納するために、まずはmoleculesテーブルを作ってみましょう。
テーブルを作成するコマンドは create table <テーブル名>(<変数名1>, <変数名2>, ...); のように打ち込みます。
ここでは『分子の名前(name)』と『分子のSMILES記法(smiles)』の二つを分子の持つべき変数として設定します。
sqlite> create table molecules(name, smiles);
文末のセミコロンは命令文の終わりを意味して、これがないと命令が実行されません。
テーブルの構造を忘れた場合は、.schema TABLE_NAMEと打つとテーブルの構造がわかります。
.schemaを使う際にはセミコロンは不要です。
sqlite> .schema molecules
CREATE TABLE molecules(name, smiles);
データの作成・変更・削除
データ作成
データを作成していきましょう。 酢酸(acetic acid, CC(O)=O)と、ピロリジン(pyrrolidine, C1CCCN1)を作成してみます。
入力には、insertコマンドを使います。
insert into <テーブル名>(<変数名1>, <変数名2>, ...) values (<変数1の値>, <変数2の値>, ...);などとします。
今回の例ですと、次のようになります。
sqlite> insert into molecules (name, smiles) values ("acetic acid", "CC(O)=O");
sqlite> insert into molecules (name, smiles) values ("pyrrolidine", "C1CCCN1");
データの読み出し
さて、入力したものを確認するにはどうしたらよいでしょう。
その際に利用するのが、select文です。
文法は、select (<変数名1>, <変数名2>, ...) from <テーブル名>;となります。
今回のmoleculesテーブルから情報を取り出します。
sqlite> select name, smiles from molecules;
すると、次のように出力されます。
acetic acid|CC(O)=O
pyrrolidine|C1CCCN1
変数名を1個だけにするとどうでしょうか。
sqlite> select name from molecules;
nameしか指定していないので、以下のように分子の名前だけ出力されます。
acetic acid
pyrrolidine
なお、個別の変数名の代わりに*を打つと、全変数の情報が出力されます。
sqlite> select * from molecules;
select name, smiles from molecules;と同じ結果が出力されます。
acetic acid|CC(O)=O
pyrrolidine|C1CCCN1
データ削除
削除するときは、delete from <テーブル名> where <データの条件>;と記述します。
<データの条件>の部分では基本的に、name = "acetic acid"のように<変数名> = "<値>"という書き方をします。
この書き方により、特定の変数が特定の値を持っているようなデータを指定することができます。
以下では、先程の続きでデータ削除の命令を入力します。
sqlite> delete from molecules where name = "acetic acid";
その後でmoleculesテーブル内のデータを確認すると、酢酸のデータが消えていることがわかります。
sqlite> select * from molecules;
pyrrolidine|C1CCCN1
テーブルの削除
テーブルを削除する際はdrop table <テーブル名>;と打ちます。
試しにatomsテーブルを作成して、レコード追加ののち削除してみましょう。
atomsテーブルを作ってから適当なデータを作成します。
sqlite> create table atoms(number, weight);
sqlite> insert into atoms (number, weight) values (8, 16);
sqlite> select * from atoms;
8|16
.schemaでatomsテーブルがあることを確認したうえで、drop tableを実行します。
sqlite> .schema atoms
CREATE TABLE atoms(number, weight);
sqlite> drop table atoms;
削除後には.schemaを入力してもなにも出力されませんし、select文でデータを取り出そうとしてもエラーが出ます。
sqlite> .schema atoms
sqlite> select * from atoms;
Error: no such table: atoms
テーブル名を間違えてしまったときなどにはdropして削除しましょう。
SQLite 3の終了
終了するときは、.quitでSQLite 3を閉じることができます。
WindowsであればCtrlキー、Macであればcommandキーを押しながらdを押しても終了できます。
SQLite 3を扱うためのソフト
コマンドラインからSQLite 3を扱う方法を説明しましたが、 ここではマウス操作で利用可能なソフトを紹介します。
無償で利用可能で操作性の良いものとしてDB Browser for SQLiteが有名かと思います。 C++という言語で記述されており、大抵のOSで利用が可能です。
Pythonから操作する場合
ここまでSQLite 3での操作方法を説明してきましたが、 Pythonと統合しようと考える人が出てきます。
Python上の変数(オブジェクト, object)とリレーショナルデータベース(relational database)をつなぐライブラリを、Object Relational (O/R) mapperなどと呼びます。 Pythonですと、SQLAlchemyや、Stormが有名なようです(私はSQLAlchemyしか使ったことがありません)。
それぞれの詳細については、ここでは省略させてもらいます。 ひとまず、Pythonからデータベースへのアクセスを容易にするライブラリがあるということを 知っておいてください。
まとめ
扱いの比較的楽な、SQLite 3について説明をしてまいりました。 最後には、SQLite 3をコマンドライン以外から操作する方法も書きました。
データが大きくなってきた際にSQLを駆使すると 出来ることが増えていきます。是非ご利用ください。